该商品专为会员推荐的商品,且该商品的学时不占用会员学时,领取该商品后需要完整观看,不能拖拽进度条快进,观看过程中会随机弹出观看互动的弹窗,需要确认后继续观看,所有弹窗都确认后,系统即认为您完成了完整的观看,才能获得该课程的学时。


商品详情页

¥130
发布
2024-04-18
 关键词
关键词
 全文摘要
全文摘要
 章节速览
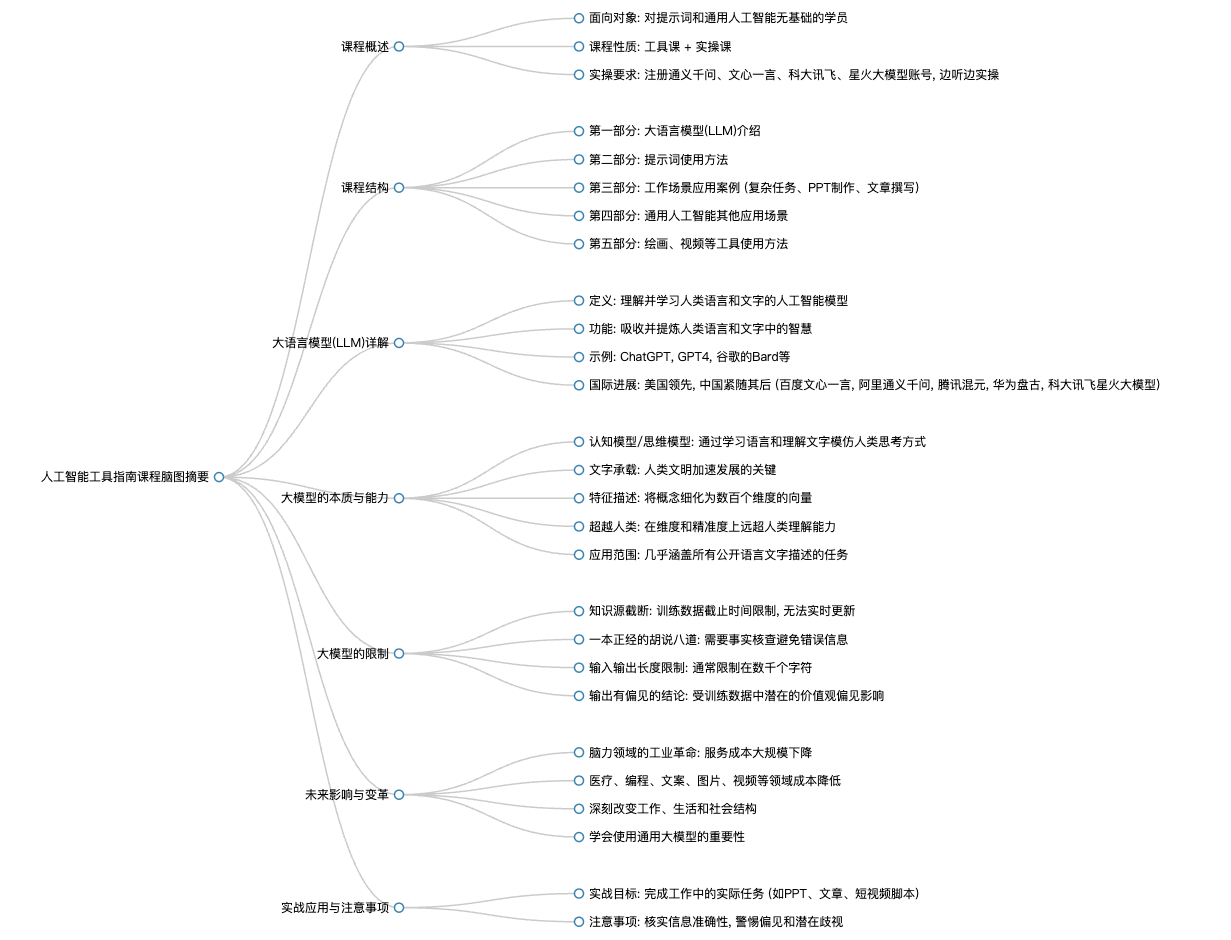
思维导图
章节速览
思维导图
 原文
原文

该课程在您的购物车中

该课程在您的待付款订单中

您已购买该课程
 您很久没更新个人信息了
您很久没更新个人信息了



